

Mínimos cuadrados
Antecedentes de las escuelas de Wikipedia
SOS Children ha intentado que el contenido de Wikipedia más accesible por esta selección escuelas. Ver http://www.soschildren.org/sponsor-a-child para averiguar sobre el apadrinamiento de niños.
El método de los mínimos cuadrados, también conocido como análisis de regresión , se utiliza para modelar los datos numéricos obtenidos a partir de observaciones mediante el ajuste de los parámetros de un modelo a fin de obtener un ajuste óptimo de los datos. El mejor ajuste se caracteriza por la suma de cuadrados de los residuos tienen su valor mínimo, una siendo residual la diferencia entre un valor observado y el valor dado por el modelo. El método fue descrito por primera vez por Carl Friedrich Gauss alrededor de 1794. mínimos cuadrados corresponde a la criterio de máxima verosimilitud si los errores experimentales tienen una distribución normal . El análisis de regresión está disponible en la mayoría paquetes de software estadístico.

Historia
Contexto
El método de los mínimos cuadrados creció fuera de los campos de la astronomía y geodesia como científicos y matemáticos trató de dar soluciones a los desafíos de la navegación océanos de la Tierra durante la Era de la Exploración . La descripción precisa del comportamiento de los cuerpos celestes fue clave para que los barcos a navegar en mar abierto donde antes marineros tenían que depender de los avistamientos de tierras para determinar las posiciones de sus naves.
El método fue la culminación de varios avances que tuvieron lugar durante el transcurso del siglo XVIII :
- La combinación de diferentes observaciones tomadas en las mismas condiciones en lugar de simplemente tratar de una mejor de observar y registrar una sola observación precisa. Este enfoque fue utilizado por particular Tobias Mayer, mientras que el estudio de la libraciones de la luna.
- La combinación de diferentes observaciones como ser la mejor estimación del valor real; errores disminuyen con la agregación en lugar de aumentar, tal vez expresado por primera Roger Cotes.
- La combinación de diferentes observaciones tomadas en diferentes condiciones como particular realizado por Roger Joseph Boscovich en su trabajo sobre la forma de la Tierra y Pierre-Simon Laplace en su trabajo en la explicación de las diferencias en el movimiento de Júpiter y Saturno .
- El desarrollo de un criterio que puede ser evaluado para determinar cuándo se ha alcanzado la solución con el mínimo error, desarrollada por Laplace en su Método de Situación.
El método en sí

Carl Friedrich Gauss se acredita con el desarrollo de los fundamentos de la base para el análisis de mínimos cuadrados en 1795 a la edad de dieciocho años.
Una demostración temprana de la fuerza del método de Gauss llegó cuando fue utilizado para predecir la futura ubicación del asteroide recién descubierto Ceres . En 1 de enero de 1801 , el astrónomo italiano Giuseppe Piazzi descubrió Ceres y fue capaz de seguir su camino por 40 días antes de que se perdió en el resplandor del sol. Basándose en estos datos, se desea determinar la localización de Ceres después de que salió de detrás del sol sin resolver el complicado ecuaciones no lineales de Kepler del movimiento planetario. Las únicas predicciones que permitieron con éxito astrónomo húngaro Franz Xaver von Zach reubicar Ceres fueron las realizadas por los 24 años de edad, Gauss utilizando el análisis de mínimos cuadrados.
Gauss no publicó el método hasta 1809 , cuando apareció en el volumen dos de su trabajo en la mecánica celeste, Theoria Motus Corporum Coelestium en sectionibus conicis Solem ambientium. En 1829 , Gauss fue capaz de afirmar que el enfoque de mínimos cuadrados para el análisis de regresión es óptima en el sentido de que en un modelo lineal en el que los errores tienen una media de cero, no están correlacionados, y tienen varianzas iguales, los mejores estimadores lineales insesgados de los coeficientes son los estimadores de mínimos cuadrados. Este resultado se conoce como el Teorema de Gauss-Markov.
La idea de mínimos cuadrados análisis también se formuló de forma independiente por el francés Adrien-Marie Legendre en 1805 y la American Robert Adrian en 1808 .
Planteamiento del problema
El objetivo consiste en ajustar los parámetros de una función de modelo con el fin de adaptarse mejor a un conjunto de datos. Un conjunto de datos simple consiste en m puntos (pares de datos)  , I = 1, ..., m, donde
, I = 1, ..., m, donde  es una variable independiente y
es una variable independiente y  es un variable dependiente cuyo valor se encuentra por la observación. La función de modelo tiene la forma
es un variable dependiente cuyo valor se encuentra por la observación. La función de modelo tiene la forma  , Donde los parámetros ajustables n se celebran en el vector
, Donde los parámetros ajustables n se celebran en el vector  . Deseamos encontrar esos valores de los parámetros para los que el modelo de "mejor" ajuste a los datos. El método de los mínimos cuadrados define "mejor" como cuando la suma, S, de los residuos al cuadrado
. Deseamos encontrar esos valores de los parámetros para los que el modelo de "mejor" ajuste a los datos. El método de los mínimos cuadrados define "mejor" como cuando la suma, S, de los residuos al cuadrado

es un mínimo. La residual se define como la diferencia entre los valores de la variable dependiente y el modelo.

Un ejemplo de un modelo es el de la línea recta. Denotando el intercepto como  y la pendiente como
y la pendiente como  , La función de modelo está dada por
, La función de modelo está dada por

Ver lineal de mínimos cuadrados # Ejemplo para un ejemplo plenamente elaborado de este modelo.
Un punto de datos puede consistir en más de una variable independiente. Para un ejemplo, en la instalación de un plano a un conjunto de mediciones de la altura, el plano es una función de dos variables independientes, x y z, por ejemplo. En el caso más general puede haber una o más variables independientes y una o más variables dependientes en cada punto de datos.
Resolver el problema de mínimos cuadrados
Menos problemas cuadrados se dividen en dos categorías, no lineal y lineal. El problema de mínimos cuadrados lineal tiene una solución de forma cerrada, pero el problema no lineal tiene que ser resuelto por el refinamiento iterativo; en cada iteración el sistema se aproxima por uno lineal, por lo que el cálculo del núcleo es similar en ambos casos.
La mínimo de la suma de cuadrados se encuentra estableciendo la gradiente a cero. Dado que el modelo contiene los parámetros n, hay n ecuaciones gradiente.

y desde 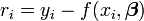 las ecuaciones se convierten en gradiente
las ecuaciones se convierten en gradiente

Las ecuaciones de gradiente se aplican a todos los problemas de mínimos cuadrados. Cada problema particular requiere expresiones particulares para el modelo y sus derivadas parciales.
Mínimos cuadrados lineales
El sistema es lineal cuando el modelo comprende una combinación lineal de los parámetros.

Los coeficientes  son constantes o funciones de la variable independiente, x i.
son constantes o funciones de la variable independiente, x i.
Desde 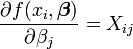 y
y  las ecuaciones se convierten en gradiente
las ecuaciones se convierten en gradiente

que, por reordenación, se convierten en ecuaciones lineales simultáneas n, las ecuaciones normales.

Las ecuaciones normales están escritos en notación matricial como

Solución de las ecuaciones normales produce los estimadores de mínimos cuadrados, 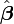 , De los valores de los parámetros. Ver mínimos cuadrados lineales (ejemplo) y de regresión lineal (ejemplo) para ejemplos numéricos elaborada.
, De los valores de los parámetros. Ver mínimos cuadrados lineales (ejemplo) y de regresión lineal (ejemplo) para ejemplos numéricos elaborada.
Mínimos cuadrados no lineales
No hay una solución cerrada a un problema no lineal de mínimos cuadrados. En lugar de ello, los valores iniciales deben ser elegidos para los parámetros. Entonces, los parámetros se refinan iterativamente, es decir, los valores se obtienen mediante aproximaciones sucesivas.

k es un número de iteración y el vector de incrementos,  que se conoce como el vector de desplazamiento. En cada iteración El modelo puede ser linealizado mediante la aproximación de primer orden en serie de Taylor de expansión sobre
que se conoce como el vector de desplazamiento. En cada iteración El modelo puede ser linealizado mediante la aproximación de primer orden en serie de Taylor de expansión sobre 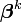

El jacobiano, J, es una función de las constantes, la variable independiente y los parámetros, por lo que cambia de una iteración a la siguiente. Los residuos se dan por

y las ecuaciones se convierten en gradiente

que, por reordenación, se convierten en ecuaciones lineales simultáneas n, las ecuaciones normales.
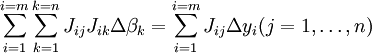
Las ecuaciones normales están escritos en notación matricial como
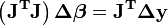
Estas son las ecuaciones que definen el Algoritmo de Gauss-Newton.
Las diferencias entre lineal y mínimos cuadrados no lineales
- La función de modelo, f, en LLSQ (lineal de mínimos cuadrados) es una combinación lineal de los parámetros de la forma
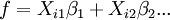 El modelo puede representar una línea recta, una parábola o cualquier otra función de tipo polinómico. En NLLSQ (mínimos cuadrados no lineales) los parámetros aparecen como funciones, tales como
El modelo puede representar una línea recta, una parábola o cualquier otra función de tipo polinómico. En NLLSQ (mínimos cuadrados no lineales) los parámetros aparecen como funciones, tales como  etcetera. Si los derivados
etcetera. Si los derivados  son constantes o sólo depende de los valores de la variable independiente, el modelo es lineal en los parámetros. De lo contrario, el modelo no es lineal.
son constantes o sólo depende de los valores de la variable independiente, el modelo es lineal en los parámetros. De lo contrario, el modelo no es lineal. - NLLSQ requiere valores iniciales para los parámetros, LLSQ no lo hace.
- NLLSQ dispone que se calcule el jacobiano. Expresiones analíticas de las derivadas parciales pueden ser complicadas. Si expresiones analíticas son imposibles de obtener las derivadas parciales se debe calcular por aproximación numérica.
- En NLLSQ divergencia es un fenómeno común, mientras que en LLSQ es bastante raro. La divergencia ocurre cuando la suma de cuadrados aumenta de una iteración a la siguiente. Es causada por la insuficiencia de la aproximación de que la serie de Taylor se puede truncar en el primer mandato. Cuando se produce la divergencia del método debe ser modificado. La Algoritmo de Levenberg-Marquardt proporciona una buena protección contra la divergencia mediante la rotación del vector de desplazamiento hacia la dirección de más empinado descenso. Por definición la convergencia está asegurada cuando los puntos de cambio de vector en la dirección de máxima pendiente.
- NLLSQ es un proceso iterativo process.The inherentemente iterativo tiene que ser terminada cuando un criterio de convergencia está satisfecho. Soluciones LLSQ se pueden calcular usando métodos directos, aunque los problemas con un gran número de parámetros normalmente se resuelven con métodos iterativos, tales como la Método de Gauss-Seidel ..
- En LLSQ la solución es única, pero en NLLSQ pueden existir mínimos múltiple en la suma de los cuadrados.
- En NLLSQ estimaciones de los errores de los parámetros son parcial, pero en LLSQ no lo son.
Estas diferencias se deben considerar cuando se busca la solución a un problema no lineal de mínimos cuadrados.
Mínimos cuadrados, el análisis de regresión y estadísticas
Los métodos de mínimos cuadrados y análisis de regresión pueden parecer diferentes métodos, pero hay similitudes sustanciales entre ellos que están ocultas por el uso de diferentes idiomas que se utilizan para describir los métodos. Ambos métodos se utilizan para modelar los datos obtenidos a partir de observaciones, y ambos pueden utilizar las mismas técnicas numéricas.
En las ciencias físicas el modelo por lo general tiene una base teórica. Por ejemplo, un resorte debe obedecer La ley de Hooke, que establece que la extensión de un resorte es proporcional a la fuerza, F, se le aplica.
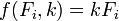
constituye el modelo, donde F es la variable independiente. Para determinar el fuerza constante, k, una serie de mediciones con diferentes fuerzas producirá un conjunto de datos,  , Donde y i es una extensión del resorte medido. La suma de cuadrados que se minimice es
, Donde y i es una extensión del resorte medido. La suma de cuadrados que se minimice es
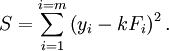
La estimación de cuadrados menos de la fuerza constante, k, está dada por

Aquí se supone que la aplicación de la fuerza hace que el resorte se expanda y, después de haber derivado la constante de fuerza por ajuste de mínimos cuadrados, la extensión se puede predecir a partir de la ley de Hooke.
En el análisis de regresión el modelo es a menudo un empírica. Por ejemplo, un modelo muy común es el modelo de línea recta que se utiliza para comprobar si existe una relación lineal entre la variable dependiente e independiente. Si no se encuentra una relación lineal de existir, se dice que son las variables correlacionadas . Sin embargo es bien sabido que la correlación no prueba la causalidad, ya que ambas variables pueden ser correlacionados con otros, ocultos, variables. Por ejemplo, existe una correlación entre las muertes por ahogamiento y el volumen de ventas de helados. Tanto el número de personas que van a nadar y el volumen de hielo aumento de las ventas de crema como se pone el clima más caliente y se puede suponer que el número de muertes por ahogamiento se correlaciona con el número de personas que van a nadar.
En ambos métodos se suele suponer que la variable independiente está libre de error, pero que la variable dependiente está sujeta a error experimental,  .
.
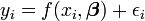
En esta expresión se supone que el valor del modelo para aproximar al valor verdadero, es decir, el valor que se observaría si no hubiera error. Se supone que el error experimental ε es una variable aleatoria con media cero, es decir, que excluye todos los errores de una carácter sistemático. Dado que el modelo es sólo una aproximación al valor verdadero, los residuos son conceptualmente diferentes de los errores. Si la variable independiente está sujeta a error, Total de mínimos cuadrados se deben utilizar.
Con el fin de hacer pruebas estadísticas en los resultados es necesario hacer suposiciones sobre la naturaleza de los errores experimentales. La suposición más común es que los errores pertenecen a una distribución normal . La teorema del límite central apoya la idea de que este es un buen supuesto en muchos casos.
- La Teorema de Gauss-Markov. En un modelo lineal en el que los errores tienen expectativa de cero, son correlacionadas y que tienen iguales varianzas , la mejor lineal estimador imparcial de cualquier combinación lineal de las observaciones, es su estimador de mínimos cuadrados. "Mejor" significa que los estimadores de mínimos cuadrados de los parámetros tienen varianza mínima. El supuesto de la igualdad de varianza es válida cuando los errores de todos pertenecen a la misma distribución.
- En un modelo lineal, si los errores pertenecen a una distribución normal también son los estimadores de mínimos cuadrados estimadores de máxima verosimilitud.
La suposición de que los errores pertenecen a una función de distribución particular, no se limita a un análisis de regresión. De hecho, tales supuestos se deben hacer al realizar pruebas estadísticas sobre los parámetros. En un cálculo de mínimos cuadrados con pesos unitarios, o en la regresión lineal, la varianza en el j-ésimo parámetro viene dado por
![\ Sigma ^ 2 (\ beta_j) = \ frac {S} {mn} \ left (\ left [X ^ TX \ right] ^ {- 1} \ right) _ {jj}.](../../images/203/20359.png)
Los límites de confianza se puede encontrar si la distribución de probabilidad se conoce de los parámetros, o asumidos. Del mismo modo las pruebas estadísticas sobre los residuos se pueden hacer si la distribución de probabilidad de los residuos es conocido o asumido. La distribución de probabilidad de cualquier combinación lineal de las variables dependientes se puede derivar, si la distribución de probabilidad de los errores experimentales se sabe o se supone. Más comúnmente se asume que los errores experimentales pertenecen a una distribución normal. En ese caso, a menudo se asume que los parámetros y los residuos pertenecen a una distribución t de Student .
La suma de los residuos al cuadrado puede ser expresado como

La matriz 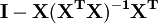 es una matriz idempotente simétrica de rango mn. Aquí está un ejemplo de la utilización de este hecho en la teoría de la regresión lineal. Los valores propios de una matriz idempotente son o bien 0 o 1. Por lo tanto mn valores propios de esta matriz son iguales a 1 y n valores propios son iguales a cero. Esa es la mayor parte del trabajo en mostrar que la suma de los cuadrados de los residuos tiene una distribución chi-cuadrado con grados de libertad mn.
es una matriz idempotente simétrica de rango mn. Aquí está un ejemplo de la utilización de este hecho en la teoría de la regresión lineal. Los valores propios de una matriz idempotente son o bien 0 o 1. Por lo tanto mn valores propios de esta matriz son iguales a 1 y n valores propios son iguales a cero. Esa es la mayor parte del trabajo en mostrar que la suma de los cuadrados de los residuos tiene una distribución chi-cuadrado con grados de libertad mn.
Mínimos cuadrados ponderados
Las expresiones dadas anteriormente se basan en la suposición implícita de que todas las medidas no están correlacionados y tienen igual incertidumbre. La Gauss-Markov teorema muestra que, cuando esto es así, es un mejor estimador lineal insesgado (AZUL). Si, sin embargo, las mediciones no están correlacionados, pero tienen diferentes incertidumbres, debe adoptarse un enfoque modificado. Aitken mostró que cuando se minimiza una suma ponderada de los residuos al cuadrado, es azul si cada peso es igual al recíproco de la varianza de la medición.

Las ecuaciones de gradiente para esta suma de cuadrados son
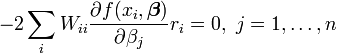
que, en un sistema de mínimos cuadrados lineal dar las ecuaciones normales modificados

o

Cuando los errores observacionales están correlacionados la matriz de pesos, W, es diagonal. Si se correlacionan los errores, la matriz de peso debe ser igual a la inversa de la matriz de varianza-covarianza de las observaciones, pero esto no afecta a la expresión de la matriz de las ecuaciones normales y las estimaciones de los parámetros son todavía AZUL. Ver Mínimos cuadrados generalizados para más detalles.
Cuando los errores no están correlacionados, es conveniente para simplificar los cálculos para factorizar la matriz de peso como 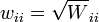 . Las ecuaciones normales se pueden entonces escribirse como
. Las ecuaciones normales se pueden entonces escribirse como

Para los sistemas no lineales de mínimos cuadrados un argumento similar muestra que las ecuaciones normales deberían modificarse de la siguiente manera.

Otros métodos
Cuadrados estimación de mínimos para los modelos lineales es notoriamente no robusto para valores atípicos. Si está sesgada la distribución de los valores atípicos, las estimaciones pueden estar sesgadas. En presencia de valores atípicos, las estimaciones de mínimos cuadrados son ineficaces y pueden ser extremadamente lento. Cuando se producen los valores atípicos en los datos, los métodos de regresión robusta son más apropiados.
La técnica de mínimos cuadrados parciales está ganando popularidad en Quimiometría y otras disciplinas. Se utiliza cuando el modelo es parcialmente conocida y parcialmente desconocida.
Los parámetros de regresión también se pueden estimar por Los métodos bayesianos. Esto tiene las ventajas que
- los intervalos de confianza pueden ser producidos para las estimaciones de los parámetros sin el uso de aproximaciones asintóticas,
- información previa puede ser incorporado en el análisis.
En la regresión lineal,

Suponemos que sabemos por el conocimiento del dominio que sólo puede tomar uno de los valores {-1, 1}, pero no sabemos cuál. Podemos construir esta información en el análisis realizado por la elección de una previa para que es una distribución discreta con una probabilidad de 0,5 en -1 y 0,5 en 1. La posterior para también será una distribución discreta en {-1, 1}, pero los pesos de probabilidad cambiarán para reflejar la evidencia de los datos.
Método Lasso
En algunos contextos una regularizado versión de la solución de mínimos cuadrados puede ser preferible. El algoritmo LASSO, por ejemplo, encuentra una solución de mínimos cuadrados con la restricción de que 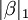 , La L 1-norma del vector de parámetros, no es mayor que un valor dado. De manera equivalente, puede resolver una minimización sin restricciones de la pena de mínimos cuadrados con
, La L 1-norma del vector de parámetros, no es mayor que un valor dado. De manera equivalente, puede resolver una minimización sin restricciones de la pena de mínimos cuadrados con  añadido, donde es una constante. (Este es el Lagrangiano dual del problema restringido.) Este problema puede ser resuelto utilizando programación cuadrática o más general métodos de optimización convexa. La L 1 -regularized formulación es útil en algunos contextos debido a su tendencia a preferir soluciones con menos valores de los parámetros distintos de cero, reduciendo efectivamente el número de variables en los que la solución dada es dependiente.
añadido, donde es una constante. (Este es el Lagrangiano dual del problema restringido.) Este problema puede ser resuelto utilizando programación cuadrática o más general métodos de optimización convexa. La L 1 -regularized formulación es útil en algunos contextos debido a su tendencia a preferir soluciones con menos valores de los parámetros distintos de cero, reduciendo efectivamente el número de variables en los que la solución dada es dependiente.
