

Distribuição t de Student
Você sabia ...
Arranjar uma seleção Wikipedia para as escolas no mundo em desenvolvimento sem internet foi uma iniciativa da SOS Children. SOS Children trabalha em 45 países africanos; você pode ajudar uma criança em África ?
Função densidade de probabilidade 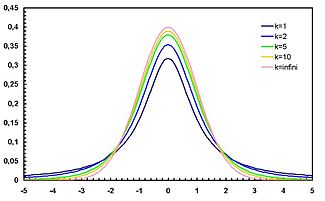 | |
Função de distribuição cumulativa 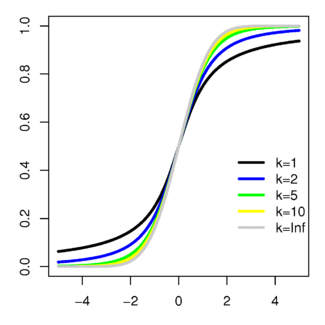 | |
| Parâmetros |  graus de liberdade ( verdadeiro ) graus de liberdade ( verdadeiro ) |
|---|---|
| Apoio | 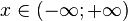 |
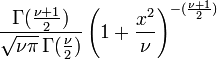 | |
| CDF | ![\ Begin {matrix} \ frac {1} {2} + x \ Gamma \ left (\ frac {\ nu + 1} {2} \ right) \ cdot \\ [0.5em] \ frac {\, _ 2F_1 \ left (\ frac {1} {2}, \ frac {\ nu + 1} {2}; \ frac {3} {2}; - \ frac {x ^ 2} {\ nu} \ right)} {\ sqrt {\ pi nu \} \, \ Gamma (\ frac {\ nu} {2})} \ end {matrix}](../../images/122/12276.png) onde 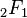 é o função hipergeométrica é o função hipergeométrica |
| Significar |  , De outra forma indefinida , De outra forma indefinida |
| Mediano |  |
| Modo | |
| Variação | 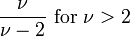 , De outra forma indefinida , De outra forma indefinida |
| Assimetria |  |
| Ex. curtose |  |
| Entropy | ![\ Begin {matrix} \ frac {\ nu + 1} {2} \ left [\ psi (\ frac {1+ \ nu} {2}) - \ psi (\ frac {\ nu} {2}) \ right ] \\ [0.5em] + \ log {\ left [\ sqrt {\ nu} B (\ frac {\ nu} {2}, \ frac {1} {2}) \ right]} \ end {matrix}](../../images/122/12283.png)
|
| MGF | (Não definido) |
 : função digamma,
: função digamma, 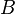 : função beta
: função beta -distribuição T de Student (ou também -distribuição t), em probabilidade e estatística , é uma distribuição de probabilidade que surge no problema de estimação da média de uma distribuição normal quando a população tamanho da amostra é pequeno. É a base do popular -Testes t de Student para a significância estatística da diferença entre duas amostras meios , e por intervalos de confiança para a diferença entre duas médias populacionais. Distribuição t de Student é um caso especial do distribuição hiperbólica generalizada.
A derivação do -distribuição t foi publicado pela primeira vez em 1908 por William Sealy Gosset, enquanto ele trabalhava em uma Guinness Brewery em Dublin . Ele foi proibido de publicar em seu próprio nome, para que o papel foi escrito sob o pseudônimo de Student. O teste t ea teoria associada tornou-se conhecido através do trabalho de RA Fisher, que telefonou para a distribuição de "distribuição de Student".
Distribuição de Student surge quando (como em quase todos os trabalhos estatísticos prático) da população desvio padrão é desconhecida e tem que ser calculada a partir dos dados. Problemas Textbook tratando o desvio padrão como se eram conhecidos são de dois tipos: (1) aqueles em que o tamanho da amostra é tão grande que se pode tratar uma estimativa da base de dados- variância como se fosse determinado, e (2) aqueles que ilustram o raciocínio matemático, em que o problema de estimar o desvio padrão é ignorado temporariamente porque esse não é o ponto que o autor ou o instrutor é então explicar.
Por que usar t -distribuição do Estudante
Intervalos de confiança e testes de hipóteses dependem -distribuição t de Student para lidar com incerteza resultante da estimativa do desvio padrão de uma amostra, enquanto que se o desvio padrão da população eram conhecidos, uma distribuição normal seria utilizada.
Como t de Student -distribuição acontece
Suponhamos que X 1, ..., X n são independentes variáveis aleatórias que são normalmente distribuídos com μ valor esperado e variância σ 2. Deixar
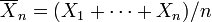
ser a média da amostra, e
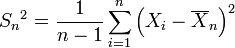
ser a variância da amostra. É facilmente mostrado que a quantidade
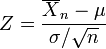
é normalmente distribuído com média 0 e variância 1, uma vez que a média da amostra 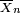 é normalmente distribuído com média
é normalmente distribuído com média 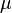 e erro padrão
e erro padrão 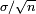 .
.
Gosset estudou um relacionado quantidade fundamental,

que difere de Z em que o desvio padrão exacto  é substituída pela variável aleatória
é substituída pela variável aleatória 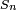 . Tecnicamente,
. Tecnicamente,  tem um
tem um  distribuição por Teorema de Cochran. O trabalho de gosset mostrou que T tem o função densidade de probabilidade
distribuição por Teorema de Cochran. O trabalho de gosset mostrou que T tem o função densidade de probabilidade
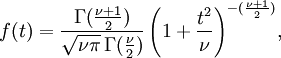
com ν igual a n - 1 e onde Γ é a Função gama.
Isto também pode ser escrita como
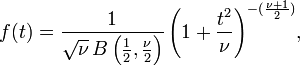
onde B é a Beta função.
A distribuição de T é agora chamado o -distribuição t. O parâmetro ν é chamado o número de graus de liberdade. A distribuição depende ν, mas não μ ou σ; a falta de dependência de μ e σ é o que faz o t -distribuição importante na teoria e na prática.
Os momentos da distribuição t são

Deve notar-se que o termo para 0 <k <ν, K mesmo, pode ser simplificada utilizando as propriedades do Função gama para

Intervalos de confiança de derivados de t de Student -distribuição
Suponhamos que o número A é escolhido de modo a que
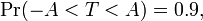
quando T tem um -distribuição t com n - 1 graus de liberdade. Este é o mesmo que
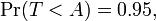
então A é o "percentil 95" desta distribuição de probabilidade, ou  . Em seguida
. Em seguida
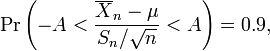
e isso é equivalente a

Por conseguinte, o intervalo cujos terminais são

está a 90 por cento intervalo de confiança para μ. Portanto, se encontramos a média de um conjunto de observações que podemos razoavelmente esperar ter uma distribuição normal, podemos usar o -distribuição t para examinar se os limites de confiança nesse média incluem algum valor previsto teoricamente - tais como o valor previsto em um hipótese nula.
É este resultado que é usado no -Testes t de Student : uma vez que a diferença entre as médias das amostras de duas distribuições normais é normalmente distribuído em si, o -distribuição t pode ser usado para examinar se a referida diferença pode ser razoavelmente suposto ser zero .
Se os dados são distribuídos normalmente, a um lado (1 - a) -upper limite de confiança (LSC) do meio, pode ser calculada usando a seguinte equação:
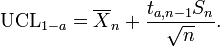
A UCL resultante será o maior valor médio que irá ocorrer para um determinado intervalo de confiança e tamanho populacional. Em outras palavras,  sendo a média do conjunto de observações, a probabilidade de que a média da distribuição é inferior aos
sendo a média do conjunto de observações, a probabilidade de que a média da distribuição é inferior aos 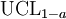 é igual ao nível de confiança
é igual ao nível de confiança 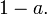
Uma série de outras estatísticas podem ser mostrados para ter -distributions t para amostras de tamanho moderado sob hipóteses nulas que são de interesse, de modo que o -distribuição t constitui a base para os testes de significância em outras situações, bem como ao examinar as diferenças entre as médias. Por exemplo, a distribuição de O coeficiente de correlação de Spearman, rho, no caso nula (correlação zero) é bem aproximada pela distribuição t para tamanhos de amostra acima de cerca de 20.
Ver intervalo de previsão para um outro exemplo do uso desta distribuição.
Integral de p-valor da função densidade de probabilidade e do Aluno
A função 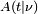 é a integral da função densidade de probabilidade de Student, ƒ (t) entre - t e t. É, assim, dá a probabilidade de que um valor de t menos do que o calculado a partir dos dados observados ocorreria por acaso. Por conseguinte, a função pode ser utilizado ao testar se a diferença entre as médias dos dois conjuntos de dados é estatisticamente significativa, através do cálculo do valor correspondente de t e a probabilidade da ocorrência do mesmo se os dois conjuntos de dados foram desenhados a partir da mesma população. Este é utilizado em uma variedade de situações, particularmente em t -Testes . Para a estatística t, com
é a integral da função densidade de probabilidade de Student, ƒ (t) entre - t e t. É, assim, dá a probabilidade de que um valor de t menos do que o calculado a partir dos dados observados ocorreria por acaso. Por conseguinte, a função pode ser utilizado ao testar se a diferença entre as médias dos dois conjuntos de dados é estatisticamente significativa, através do cálculo do valor correspondente de t e a probabilidade da ocorrência do mesmo se os dois conjuntos de dados foram desenhados a partir da mesma população. Este é utilizado em uma variedade de situações, particularmente em t -Testes . Para a estatística t, com  graus de liberdade, é a probabilidade de que t que ser menor do que o valor observado se os dois meios foram as mesmas (desde que a média mais pequena é subtraído do maior, de modo que t> 0). Ela é definida para verdadeiro t pela seguinte fórmula:
graus de liberdade, é a probabilidade de que t que ser menor do que o valor observado se os dois meios foram as mesmas (desde que a média mais pequena é subtraído do maior, de modo que t> 0). Ela é definida para verdadeiro t pela seguinte fórmula:

onde B é a Beta função. Para t> 0, não há uma relação para a regularização função beta incompleta I x (a, b) como se segue:
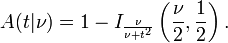
A probabilidade de um valor de a estatística t maior do que ou igual ao observado que acontecem por acaso, se os dois conjuntos de dados foram desenhados a partir da mesma população, é dada pela
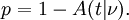
Além disso teoria
O resultado de Gosset pode ser indicado de forma mais geral. (Veja, por exemplo, Hogg e Craig, Seções 4.4 e 4.8.) Deixe-Z tem uma distribuição normal com média 0 e variância 1. Seja V tem uma distribuição qui-quadrado com graus de liberdade ν. Suponha ainda que Z e V são independente (ver Teorema de Cochran). Em seguida, o rácio

tem uma -distribuição t com ν graus de liberdade.
Para um -distribuição t com ν graus de liberdade, o valor esperado é 0, e a sua variação é ν / (ν - 2) se ν> 2. O assimetria é 0 eo curtose é 6 / (ν - 4) se ν> 4.
O função de distribuição cumulativa é dada por um função beta incompleta,
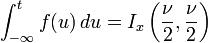
com
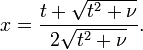
O -distribuição t está relacionada com a F-distribuição da seguinte forma: o quadrado de um valor de t, com graus de liberdade ν é distribuído como F com 1 e ν graus de liberdade.
A forma geral da função densidade de probabilidade da -distribuição t lembra o formato de um sino normalmente distribuído variável com média 0 e variância 1, exceto que ele é um pouco menor e mais amplo. À medida que o número de graus de liberdade cresce, o -distribuição t se aproxima da distribuição normal com média e variância 0 1.
As imagens seguintes mostram a densidade do -distribuição t para aumentar valores de ν. A distribuição normal é mostrado como uma linha azul para a comparação .; Note-se que o t -distribuição (linha vermelha) torna-se mais próxima da distribuição normal como ν aumenta. Para ν = 30 a -distribuição t é quase a mesma que a distribuição normal.
 |  |  |
 |  |  |
Tabela de valores seleccionados
A tabela a seguir lista alguns valores selecionados para t-distribuições com ν graus de liberdade para uma série de intervalos de confiança unilaterais. Para um exemplo de como ler a tabela, dê a quarta linha, que começa com 4; isso significa que ν, o número de graus de liberdade, é de 4 (e se estamos lidando, como acima, com valores de n com um montante fixo, n = 5). Pegue a quinta entrada, na coluna 95%. O valor dessa entrada é "2.132". Então a probabilidade de que T é inferior a 2,132% ou 95 é 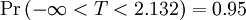 ; a entrada não significa (como pôde com outras distribuições) que
; a entrada não significa (como pôde com outras distribuições) que  .
.
Na verdade, pelo simetria da distribuição,
- Pr (T <-2,132) = 1 - Pr (T> -2,132) = 1-0,95 = 0,05,
então
- Pr (-2,132 <t <2,132) = 1 - 2 (0,05) = 0,9.
Note-se que a última linha também dá pontos críticos: a -distribuição t com infinitamente muitos graus de liberdade é uma distribuição normal. (Veja abaixo: distribuições relacionadas).
 | 75% | 80% | 85% | 90% | 95% | 97,5% | 99% | 99,5% | 99,75% | 99,9% | 99,95% |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1,000 | 1.376 | 1.963 | 3.078 | 6,314 | 12,71 | 31.82 | 63,66 | 127,3 | 318,3 | 636,6 |
| 2 | 0,816 | 1.061 | 1.386 | 1.886 | 2.920 | 4,303 | 6,965 | 9,925 | 14.09 | 22.33 | 31,60 |
| 3 | 0,765 | 0,978 | 1.250 | 1.638 | 2.353 | 3,182 | 4.541 | 5,841 | 7,453 | 10,21 | 12,92 |
| 4 | 0,741 | 0,941 | 1.190 | 1.533 | 2.132 | 2,776 | 3,747 | 4,604 | 5,598 | 7,173 | 8.610 |
| 5 | 0,727 | 0,920 | 1.156 | 1.476 | 2.015 | 2.571 | 3.365 | 4,032 | 4,773 | 5,893 | 6,869 |
| 6 | 0,718 | 0,906 | 1.134 | 1.440 | 1.943 | 2,447 | 3,143 | 3,707 | 4,317 | 5,208 | 5,959 |
| 7 | 0,711 | 0,896 | 1.119 | 1.415 | 1.895 | 2.365 | 2.998 | 3,499 | 4,029 | 4,785 | 5,408 |
| 8 | 0,706 | 0,889 | 1.108 | 1.397 | 1.860 | 2.306 | 2.896 | 3.355 | 3.833 | 4,501 | 5,041 |
| 9 | 0,703 | 0,883 | 1.100 | 1.383 | 1.833 | 2.262 | 2,821 | 3.250 | 3,690 | 4,297 | 4,781 |
| 10 | 0.700 | 0,879 | 1.093 | 1.372 | 1.812 | 2.228 | 2.764 | 3.169 | 3.581 | 4,144 | 4,587 |
| 11 | 0,697 | 0,876 | 1.088 | 1.363 | 1,796 | 2.201 | 2.718 | 3.106 | 3,497 | 4,025 | 4,437 |
| 12 | 0,695 | 0,873 | 1.083 | 1.356 | 1.782 | 2.179 | 2,681 | 3,055 | 3.428 | 3.930 | 4,318 |
| 13 | 0,694 | 0,870 | 1.079 | 1.350 | 1.771 | 2.160 | 2.650 | 3.012 | 3,372 | 3.852 | 4,221 |
| 14 | 0,692 | 0,868 | 1.076 | 1.345 | 1.761 | 2.145 | 2,624 | 2,977 | 3,326 | 3.787 | 4.140 |
| 15 | 0,691 | 0,866 | 1.074 | 1.341 | 1.753 | 2.131 | 2,602 | 2,947 | 3.286 | 3,733 | 4,073 |
| 16 | 0.690 | 0,865 | 1.071 | 1.337 | 1.746 | 2.120 | 2.583 | 2,921 | 3.252 | 3,686 | 4,015 |
| 17 | 0,689 | 0,863 | 1.069 | 1.333 | 1.740 | 2.110 | 2.567 | 2,898 | 3.222 | 3.646 | 3.965 |
| 18 | 0,688 | 0,862 | 1.067 | 1.330 | 1.734 | 2.101 | 2,552 | 2.878 | 3,197 | 3.610 | 3,922 |
| 19 | 0,688 | 0,861 | 1.066 | 1.328 | 1.729 | 2,093 | 2.539 | 2,861 | 3.174 | 3,579 | 3,883 |
| 20 | 0,687 | 0,860 | 1.064 | 1.325 | 1.725 | 2.086 | 2,528 | 2.845 | 3.153 | 3,552 | 3.850 |
| 21 | 0,686 | 0,859 | 1.063 | 1.323 | 1.721 | 2.080 | 2.518 | 2.831 | 3.135 | 3,527 | 3,819 |
| 22 | 0,686 | 0,858 | 1.061 | 1.321 | 1.717 | 2.074 | 2.508 | 2,819 | 3.119 | 3.505 | 3.792 |
| 23 | 0,685 | 0,858 | 1.060 | 1.319 | 1.714 | 2.069 | 2,500 | 2.807 | 3.104 | 3.485 | 3,767 |
| 24 | 0,685 | 0,857 | 1.059 | 1.318 | 1.711 | 2.064 | 2.492 | 2,797 | 3.091 | 3.467 | 3,745 |
| 25 | 0,684 | 0,856 | 1.058 | 1.316 | 1.708 | 2.060 | 2,485 | 2,787 | 3.078 | 3.450 | 3,725 |
| 26 | 0,684 | 0,856 | 1.058 | 1.315 | 1.706 | 2.056 | 2,479 | 2.779 | 3.067 | 3,435 | 3,707 |
| 27 | 0,684 | 0,855 | 1.057 | 1.314 | 1.703 | 2.052 | 2,473 | 2,771 | 3.057 | 3.421 | 3,690 |
| 28 | 0,683 | 0,855 | 1.056 | 1.313 | 1.701 | 2.048 | 2.467 | 2.763 | 3,047 | 3,408 | 3,674 |
| 29 | 0,683 | 0,854 | 1.055 | 1.311 | 1.699 | 2.045 | 2.462 | 2.756 | 3,038 | 3.396 | 3,659 |
| 30 | 0,683 | 0,854 | 1.055 | 1.310 | 1.697 | 2.042 | 2.457 | 2.750 | 3.030 | 3,385 | 3.646 |
| 40 | 0,681 | 0,851 | 1.050 | 1.303 | 1.684 | 2,021 | 2.423 | 2.704 | 2.971 | 3,307 | 3.551 |
| 50 | 0,679 | 0,849 | 1.047 | 1.299 | 1.676 | 2.009 | 2.403 | 2,678 | 2.937 | 3.261 | 3.496 |
| 60 | 0,679 | 0,848 | 1.045 | 1.296 | 1.671 | 2.000 | 2.390 | 2.660 | 2,915 | 3,232 | 3.460 |
| 80 | 0,678 | 0,846 | 1.043 | 1.292 | 1.664 | 1.990 | 2.374 | 2.639 | 2,887 | 3,195 | 3.416 |
| 100 | 0,677 | 0,845 | 1.042 | 1.290 | 1.660 | 1.984 | 2,364 | 2,626 | 2.871 | 3.174 | 3.390 |
| 120 | 0,677 | 0,845 | 1.041 | 1.289 | 1.658 | 1.980 | 2,358 | 2.617 | 2.860 | 3.160 | 3.373 |
 | 0,674 | 0,842 | 1.036 | 1.282 | 1.645 | 1.960 | 2.326 | 2,576 | 2.807 | 3.090 | 3.291 |
Veja também t-mesa .
O número no início de cada linha da tabela acima é ν que foi acima definido como n - 1. A percentagem ao longo do topo é 100% (1 - α). Os números no corpo principal da tabela são t α, ν. Se uma quantidade T é distribuída como a distribuição t de Student com graus ν de liberdade, em seguida, existe uma probabilidade de 1 -. Α que t vai ser menor do que o t α, ν (calculado como por um teste unilateral ou unilateral conforme oposição a um bicaudal teste.)
Por exemplo, dada uma amostra com uma variância da amostra 2 e média da amostra de 10, feita a partir de um conjunto de amostras de 11 (10 graus de liberdade), usando a fórmula
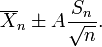
Podemos determinar que pelo 90% de confiança, nós temos uma média verdadeira deitado abaixo

(Por outras palavras, em média, 90% das vezes que um limite superior é calculada por este método, a média verdadeira encontra-se abaixo deste limiar superior.) E, ainda em 90% de confiança, que tem uma média verdadeira deitada sobre

(Por outras palavras, em média, 90% das vezes que um limite inferior é calculada por este método, a média verdadeira se encontra acima deste limite inferior). Assim que a 80% de confiança, que tem uma média verdadeira situada entre
![10 \ pm1.37218 \ frac {\ sqrt {2}} {\ sqrt {11}} = [9,41490, 10,58510].](../../images/123/12345.png)
(Por outras palavras, em média, 80% das vezes que os limiares superior e inferior são calculados por este método, a média verdadeira é tanto abaixo do limiar superior e acima do limiar mais baixo. Este não é o mesmo que dizer que existe uma probabilidade de 80% que a média verdadeira situa-se entre um par particular de limiares superior e inferior que têm sido calculadas por este método - ver intervalo de confiança e falácia do procurador.)
Para obter informações sobre a função de distribuição cumulativa inversa ver Quantile função.
Casos especiais
Certos valores de ν dar uma forma especialmente simples.
ν = 1
Função de distribuição:
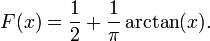
Função de densidade:

Ver Distribuição Cauchy
ν = 2
Função de distribuição:
![F (x) = \ frac {1} {2} \ left [1 + \ frac {x} {\ sqrt {2 + x ^ 2}} \ right].](../../images/123/12348.png)
Função de densidade:

Modelagem paramétrica robusta
O -distribuição t é frequentemente utilizado como uma alternativa para a distribuição normal como um modelo para os dados. É frequentemente o caso que os dados reais têm caudas mais pesadas do que a distribuição normal permite. A abordagem clássica foi identificar casos anómalos e excluir ou downweight-los de alguma forma. No entanto, nem sempre é fácil de identificar valores extremos (especialmente nas elevadas dimensões), e o -distribuição t é uma escolha natural de modelo para esses dados e fornece um método paramétrico de estatísticas robustas.
Lange et al exploraram o uso da -distribuição t para a modelagem robusta de dados pesados de cauda em uma variedade de contextos. Uma conta de Bayesian pode ser encontrado em Gelman et al. Os graus de liberdade parâmetro controla a curtose da distribuição e é correlacionada com o parâmetro de escala. A probabilidade pode ter múltiplas máximas locais e, como tal, é muitas vezes necessário fixar os graus de liberdade a um valor relativamente baixo e estimar os outros parâmetros, tendo isso como dado. Alguns autores relatam que valores entre 3 e 9 são muitas vezes boas escolhas. Venables e Ripley sugerem que um valor de 5 é muitas vezes uma boa escolha.
Distribuições relacionados
 tem um t -distribuição se
tem um t -distribuição se  tem um escalados inverse- χ 2 distribuição e
tem um escalados inverse- χ 2 distribuição e  tem uma distribuição normal .
tem uma distribuição normal . 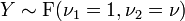 tem um F -distribuição se
tem um F -distribuição se  e
e 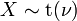 -distribuição tem t de Student.
-distribuição tem t de Student.  tem uma distribuição normal quanto
tem uma distribuição normal quanto 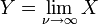 onde .
onde .  tem um Distribuição Cauchy se
tem um Distribuição Cauchy se  .
.
